系统界面
任务配置界面
首页
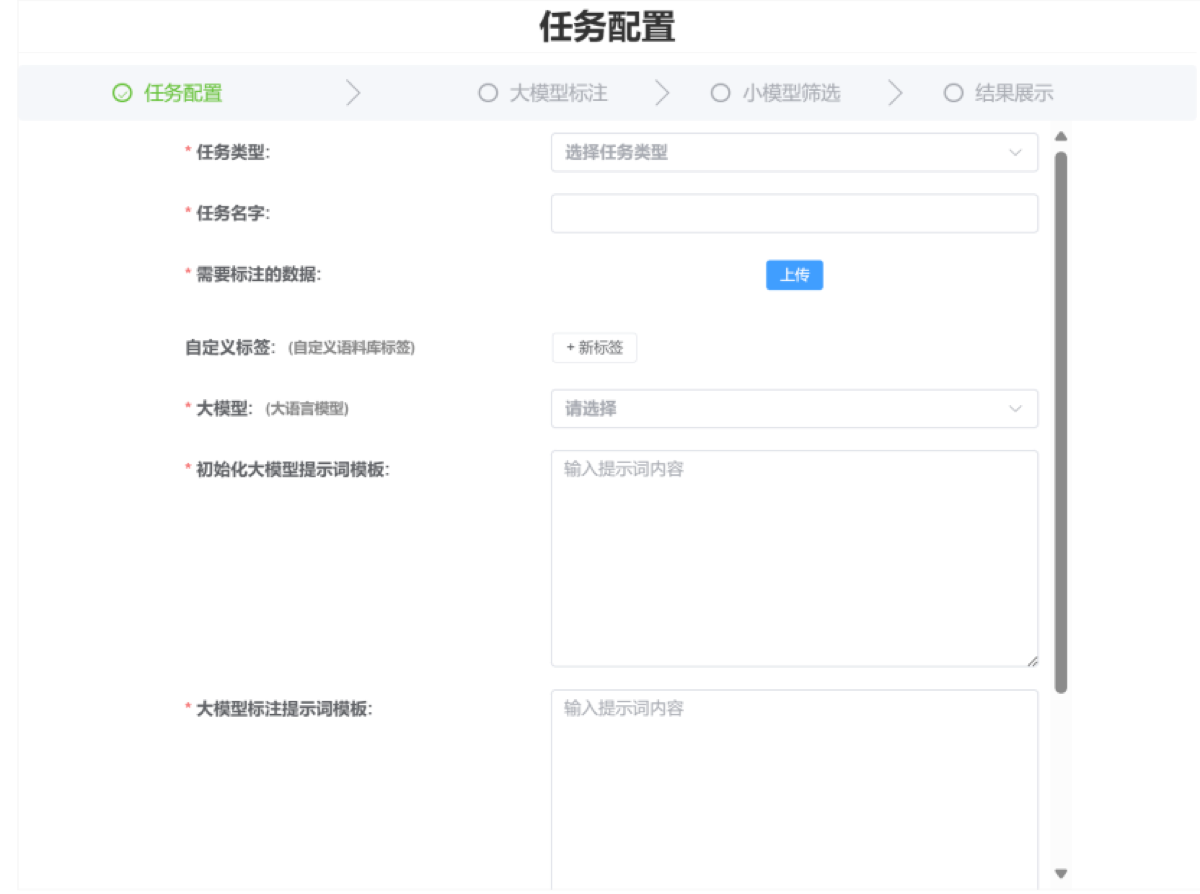
任务配置界面
支持标注任务参数设置、标签体系选择等功能
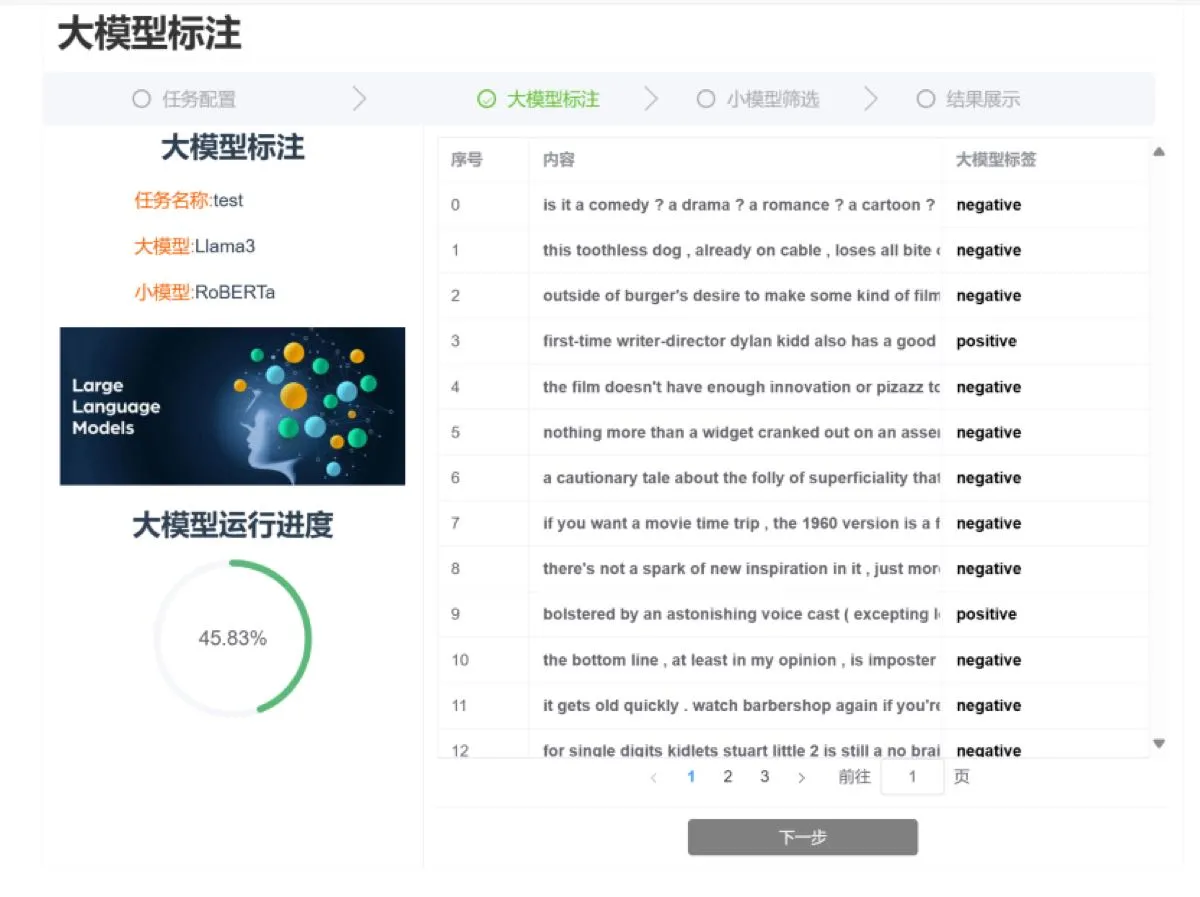
标注可视化界面
大模型标注过程实时可视化展示
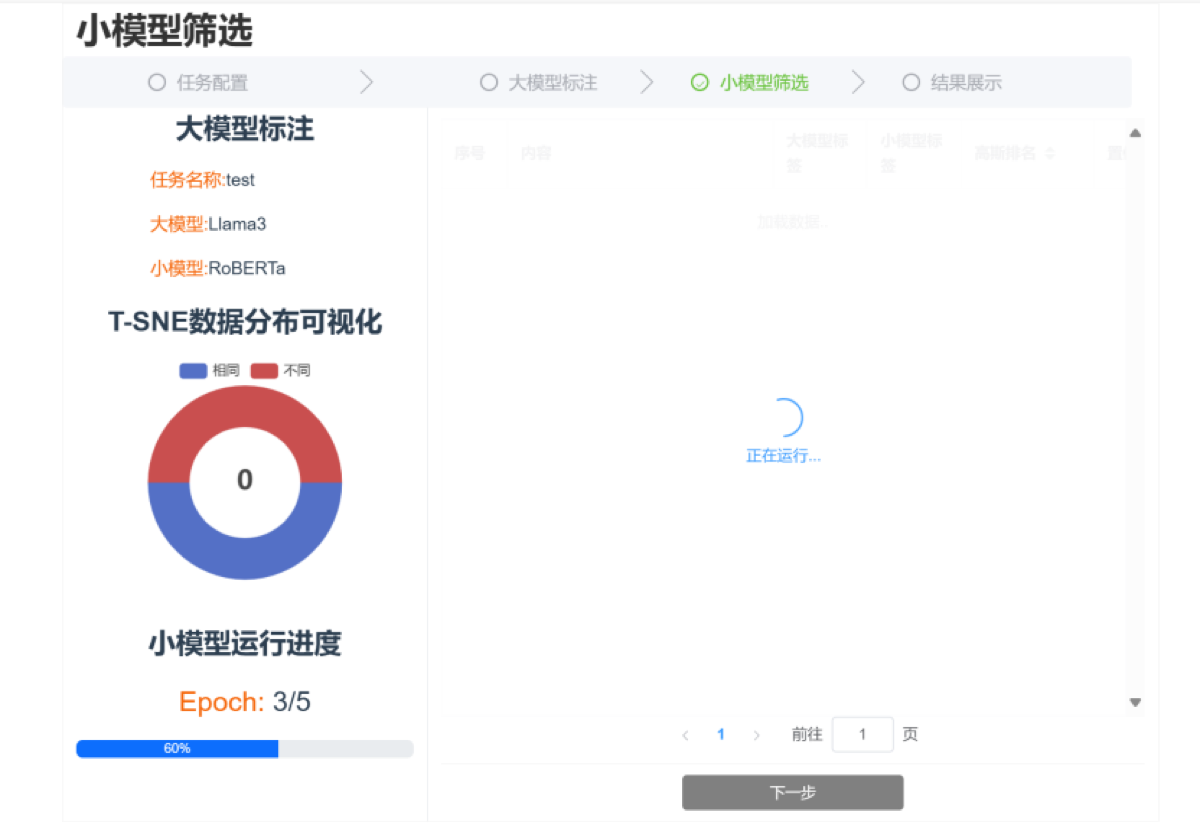
质量筛选界面
小模型筛选结果与置信度展示
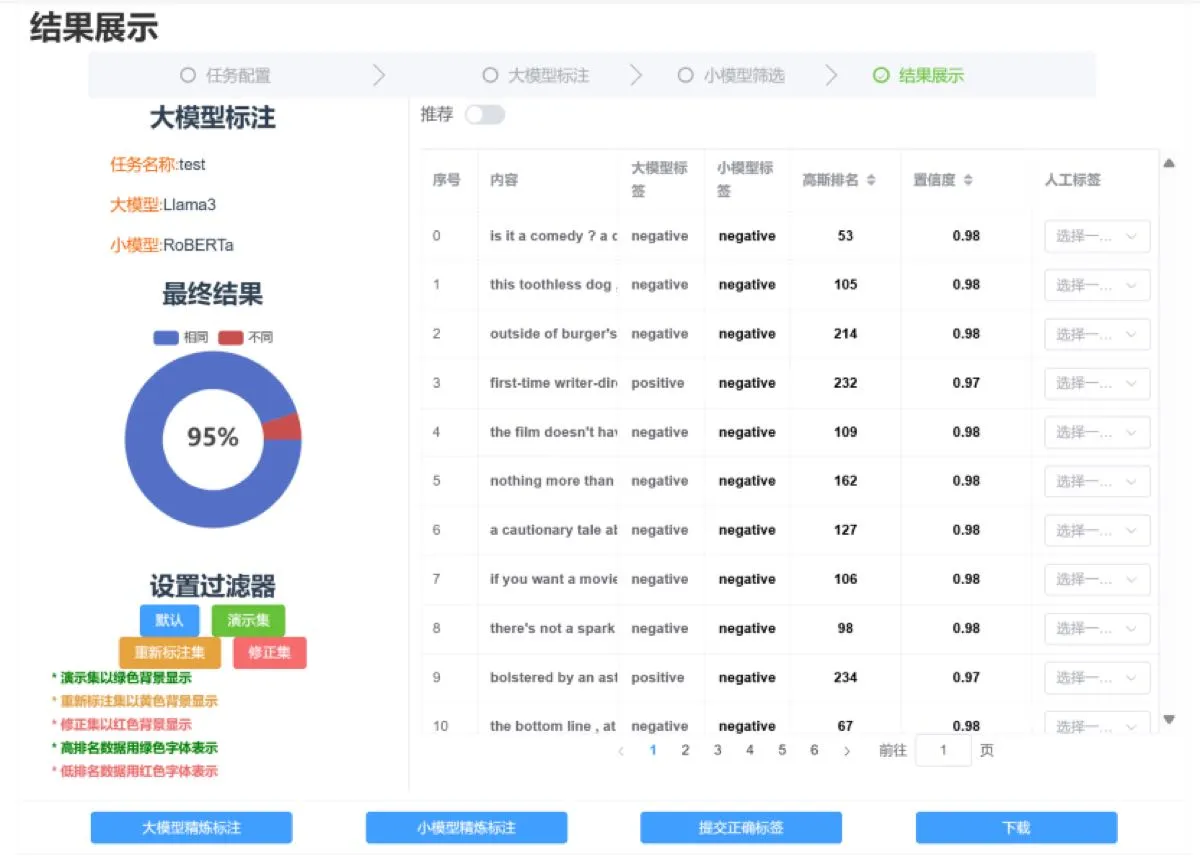
效果统计界面
标注质量评估与迭代效果分析
提出"大模型初标-小模型筛选-人工复核"协同机制,实现高效低成本的文本数据自动标注,显著降低人工标注成本约 80%-90%。
利用大语言模型(LLM)的强大生成能力进行冷启动,通过上下文学习实现零样本/少样本自动标注。
引入高斯混合模型进行置信度评估,筛选高质量标注样本,实现知识蒸馏与迭代优化。
仅对低置信度样本进行人工修正,人力成本仅占约5%,大幅降低标注总成本。
首页
支持标注任务参数设置、标签体系选择等功能
大模型标注过程实时可视化展示
小模型筛选结果与置信度展示
标注质量评估与迭代效果分析
任务配置、标注可视化、效果统计、人工修正等交互功能
大模型标注、小模型筛选、人工辅助、迭代控制
语料管理、提示模板库、大小模型接口管理
已部署至分布式集群,支持中大规模文本数据处理
系统已成功申请软件著作权(登记号:2025SR0655543),功能完整,具备实用能力。
研究成果在 ACM 期刊发表,提出基于大语言模型的协作式自动标注系统 CORAL。
《Multi-Agent Managed Multi-Source Annotation System》在 EMNLP 期刊发表。
《Dual Graph Disambiguation for Multi-Instance Partial-Label Learning》在 AAAI 发表。